트라이(Trie)란?
트라이(Trie, Prefix Tree)는 문자열을 효율적으로 저장하고 검색하기 위한 트리(Tree) 자료구조이다.
특히 문자열 탐색, 자동 완성(Autocomplete), 사전(Dictionary) 검색 등에 자주 사용된다.
1. 트라이(Trie)의 특징
✅ 루트노드는 항상 비어있음
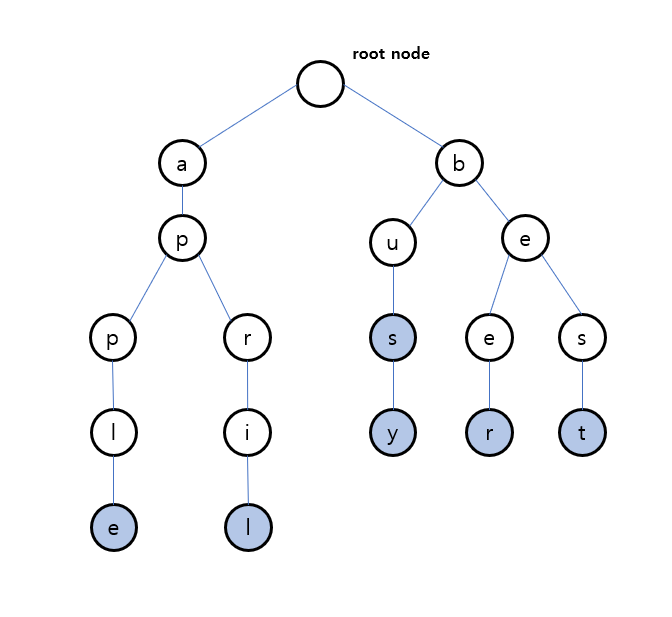
✅ 문자열의 공통 접두사를 공유하여 저장 (Prefix Sharing) - 루트노드의 자식노드는 단어의 첫 글자
✅ 검색이 O(m) (m = 문자열 길이)로 매우 빠름
✅ 사전(Dictionary), 자동 완성(Auto-complete), 검색 제안 등에 사용됨
✅ 메모리 사용량이 많을 수 있음 (노드 개수 증가)
2. 트라이(Trie)의 구조
트라이는 루트(Root) 노드에서 시작해 각 문자(Character)를 노드로 연결하는 트리 구조를 가집니다.
public class Trie {
Node root;
public Trie() {
this.root = new Node();
}
public void insert(String str);
boolean search(String str);
public boolean delete(String str);
}📌 트라이 노드(Trie Node)
- 문자(Character)를 저장.
- 다음 문자(자식 노드)로의 링크(포인터) 포함.
- 단어의 끝인지 여부를 나타내는 플래그(Flag) 존재.
class Node{
HashMap<Character, Node> child;
boolean endOfWord;
}📌 예제: "cat", "car", "dog"을 저장한 트라이
(root)
├── c
│ ├── a
│ │ ├── t (*단어 끝)
│ │ ├── r (*단어 끝)
├── d
│ ├── o
│ │ ├── g (*단어 끝)
3. 트라이(Trie) 연산
| 연산 | 설명 | 시간복잡도 |
| 삽입(Insert) | 문자열을 한 글자씩 노드에 추가 | O(m) (m=문자열 길이) |
| 검색(Search) | 특정 문자열이 존재하는지 확인 | O(m) |
| 삭제(Delete) | 특정 문자열을 제거 | O(m) |
📌 (1) 삽입(Insert) - O(m)
- 루트에서 시작하여 문자열의 각 문자(char)를 탐색.
- 해당 문자가 없으면 새로운 노드를 생성.
- 문자열 끝이면 단어 종료 표시.
public void insert(String str) {
// 시작 노드를 루트 노드로 설정
Node node = this.root;
// 문자열의 각 문자(char) 순회
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
// 자식 노드 중 해당 문자가 없으면 새로운 노드 추가
node.child.putIfAbsent(c, new Node());
// 해당 문자의 자식 노드로 이동
node = node.child.get(c);
}
// 단어의 끝을 표시 - for문이 종료되면 현재 노드는 마지막 글자임
node.endOfWord = true;
}📌 (2) 검색(Search) - O(m)
- 루트에서 시작하여 문자열의 각 문자(char)를 따라가며 노드를 탐색.
- 마지막 노드가 단어 끝(is_end=True)이면 단어 존재.
public boolean search(String str) {
Node node = this.root;
// 문자열의 각 문자(char) 순회
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
// 현재 노드의 자식 노드에 해당 문자가 없으면 검색 실패
if (!node.child.containsKey(c)) {
return false;
}
// 다음 자식 노드로 이동
node = node.child.get(c);
}
// 마지막 노드의 endOfWord 값 반환 (단어가 완전히 존재하는지 확인)
// true인지 확인한다.
return node.endOfWord;
}📌 (3) 삭제(Delete) - O(m)
- 루트에서 시작하여 문자열을 탐색.
- 마지막 문자의 단어 끝 표시를 제거.
- 불필요한 노드(자식이 없는 노드)는 삭제.
// 사용자가 삭제 요청 시 호출하는 메서드
public boolean delete(String str) {
return delete(this.root, str, 0);
}
// 내부적으로 재귀를 통해 삭제하는 메서드
private boolean delete(Node node, String str, int idx) {
if (idx == str.length()) { // 문자열 끝에 도달했을 때
if (!node.endOfWord) return false; // 단어가 존재하지 않음
// 단어의 끝을 false로 변경하여 삭제된 것처럼 처리
node.endOfWord = false;
// 자식 노드가 없으면 삭제 가능
return node.child.isEmpty();
}
char c = str.charAt(idx);
// 현재 노드에 해당 문자가 없으면 삭제 불가능
if (!node.child.containsKey(c)) return false;
Node nextNode = node.child.get(c);
// 재귀 호출을 통해 다음 노드를 처리
boolean shouldDeleteCurrentNode = delete(nextNode, str, idx + 1);
// 자식 노드를 삭제할 필요가 있는 경우 처리
if (shouldDeleteCurrentNode) {
node.child.remove(c);
// 현재 노드가 단어의 끝이 아니고, 자식 노드가 없다면 삭제 가능
return !node.endOfWord && node.child.isEmpty();
}
return false;
}더보기
삭제 로직 - 코드 흐름 정리
- 문자열 끝까지 도달했는지 확인
- 도달했다면 endOfWord를 false로 변경 (단어 삭제).
- 해당 노드의 자식이 없다면 true 반환 (부모 노드에서 제거 가능).
- 현재 문자가 자식 노드에 있는지 확인
- 없으면 false 반환 (삭제 불가능).
- 재귀적으로 다음 문자에 대해 삭제 실행
- shouldDeleteCurrentNode를 받아, 필요하면 현재 노드 삭제.
- 현재 노드를 삭제할 조건 확인
- 단어의 끝이 아니고, 자식 노드가 없다면 삭제 가능.
4. 트라이(Trie) 활용 사례
| 사용 | 사례 설명 |
| 자동 완성(Auto-Complete) | 검색창에서 입력 시 추천어 제공 (Google 검색) |
| 사전(Dictionary) 검색 | 문자열 탐색, 단어 존재 여부 확인 |
| IP 주소 필터링 | 네트워크에서 빠른 탐색 |
| 문자열 패턴 매칭 | 특정 문자열이 포함된 문장 검색 |
6. 트라이(Trie)의 장단점
| 장점 | 단점 |
| 문자열 검색이 빠름 (O(m)) | 메모리 사용량이 큼 (많은 노드 생성) |
| 공통 접두사를 공유하여 저장 | 문자열이 적을 경우 비효율적 |
| 자동 완성 기능에 적합 | 비교적 구현이 복잡함 |
7. 정리
✅ 트라이(Trie)는 문자열 검색을 빠르게 수행하는 자료구조
✅ O(m)의 탐색 속도로 해시 테이블보다 접두사 검색에 유리
✅ 검색 엔진 자동 완성, 사전 검색, 문자열 패턴 매칭에 활용
✅ 메모리 사용량이 많아지는 단점이 있음
참고자료
https://innovation123.tistory.com/116
'Development > CS' 카테고리의 다른 글
| [JAVA - 면접 대비] 자바와 절차적/구조적 프로그래밍 (0) | 2025.02.14 |
|---|---|
| [스프링 입문을 위한 자바 객체지향의 원리와 이해] 2장. 자바와 절차적/ 구조적 프로그래밍 (0) | 2025.02.12 |
| [면접을 위한 CS 전공 지식 노트] 5장. 자료구조 (0) | 2025.01.29 |
| 클러스터 인덱스(Clustered Index)와 넌클러스터 인덱스(Non-Clustered Index) (0) | 2025.01.24 |
| [면접을 위한 CS 전공 지식 노트] 4장. 데이터베이스 (0) | 2025.01.22 |